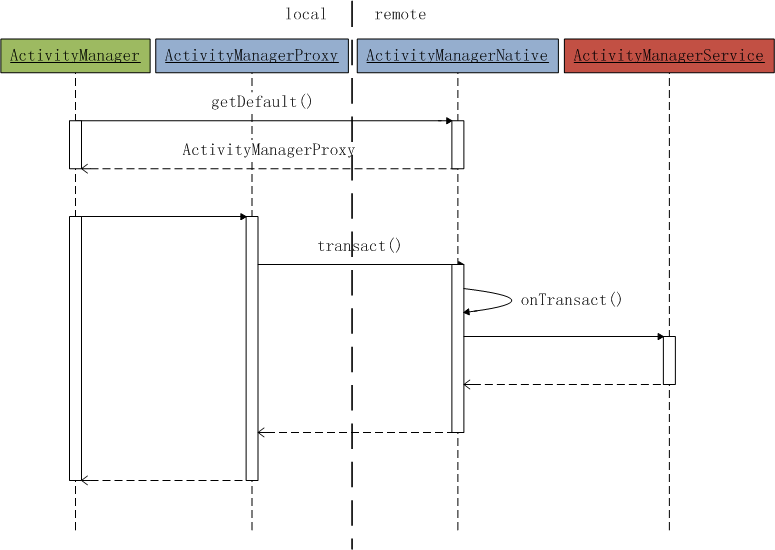
Version | Date | Creator | Description |
1.0.0 .1 | 2004-9-06 | 郑昀 掌上灵通 | 草稿 |
|
|
|
|
摘要:
本文档详细介绍了网页数据采集系统的架构和运行机理。
第一章简单介绍了Spider的设计意图和模块构成。
第二章简单介绍了Spider.Crawler层如何抓取网页并落地。
第三章简单介绍了Spider.Parser层如何解析落地网页,并生成数据XML文件。
第四章简单介绍了Spider.Saver层如何解析落地XML文件,并生成SQL语句,同时插入数据库记录。
1概述
摘要:本章节简单介绍了Spider的设计意图和模块构成。
彩铃/炫铃数据采集子系统由以下几个模块构成:
n 网页抓取层
n 网页解析层
n 数据自动存储层
n 数据库
下面简单地对这四层做一个总体描述:
1.1.网页抓取层
本层负责从各地不同运营商的不同平台的数据门户抓取HTML页面,并存储在本地目录下。
存取的路径如图所示:
图1-1 存储文件夹树状结构
本层只负责抓取网页并落地,一旦落地成功,就发送MSMQ消息通知下一层去解析它。
1.2.网页解析层
网页解析层负责监听MSMQ消息队列中的网页落地消息。
一旦有消息到来,本层就得到了网页落地的路径以其他参数。
本层将会去读取该网页文件内容,利用C#的正则表达式处理模块得到业务数据。
得到数据之后,将把该数据保存为指定格式的XML文件,落地到相同目录下;然后同样用MSMQ消息通知下一层去处理。
1.3.数据自动存储层
数据自动存储层负责监听MSMQ消息队列中的网页解析消息。
一旦有消息到来,本层就得到了解析后的XML文件落地的路径以其他参数。
本层其实只是用XSLT对XML做Transform,得到最后要执行的SQL语句。
然后执行该SQL语句,将数据存储入对应的日统计表中,这些日统计表对应于移动门户的每日每个时段。比如,日统计表的命名规范可以是:
%移动运营商名称缩写% +
%日期% +
%时段% +
%类型%
。
1.4.数据库
数据库层提供数据服务。
目前采用的数据库是MSSqlServer。
架构图如下所示:
图 1-1 架构图
2 网页抓取层-Spider.Crawler
摘要:本章节简单介绍了Spider.Crawler层如何抓取网页并落地。
2.1.抓取背景知识
获取远端网页,可以用MSXML3.ServerXMLHTTP接口。用这个接口抓取网页有这么几个好处:
| ServerXMLHTTP优点 |
1 | Allows configuring timeouts when sending messages |
2 | The ServerXMLHTTP component does not impose any limits on the number of connections to a server |
3 | ServerXMLHTTP does not implement a cache |
表2-1 SXH优点
对于移动彩铃门户,网页速度是非常缓慢的,所以我们必须设置好请求网页的超时时间,以便重试。
SXH接口不限制连接数量,恰恰是我们需要的。我们可能开许多个并发连接到各个门户。
SXH接口没有实现缓存Cache,这样我们不用担心抓取到网页过时数据。
当然也有缺点:
| ServerXMLHTTP缺点 |
1 | ServerXMLHTTP does not support any auto-detection or discovery of proxy servers; you must explicitly specify the name of the proxy server using the proxycfg.exe utility. Can be configured with WinHTTP proxy config to access other machines directly (no proxy server). |
表2-2 SXH缺点
这样在异端代理服务器环境中,也许需要专门指定代理服务器才可以访问Internet。在实施中会是一个风险点。
2.2.并发抓取
我们可以设置配置文件,来动态要求网页抓取服务起多少个抓取线程,每个线程针对特定的门户抓取总排行榜。
2.3.网页落地
我们规定好网页落地的文件夹规则,抓取线程负责落地。如果文件夹不存在,那么就自动创建。
我们还要负责网页HTML文件的命名规则,比如TotalNo1.htm、TotalNo2.htm。
2.4.通知网页解析层处理落地文件
网页落地后,需要用MSMQ消息队列来通知网页解析服务有新文件要处理了。
用MSMQ消息队列作中间介质的优点是:
l 便于异步处理;
l 消息不会丢失;
l 将网页抓取速度和网页解析速度分离开来,免得形成性能瓶颈,因为一般解析速度是很快的,而下载网页速度却不一定,甚至于超时失败。
3 网页解析层-Spider.Parser
摘要:本章节简单介绍了Spider.Parser层如何解析落地网页,并生成数据XML文件。
3.1.解析背景知识
本来是想用IE WebControl解析网页得到特定网页中的特定数据:
Set oDocument = Form2.m_IE.Document
Set oelement = oDocument.Forms("searchdetail")
Set oListTableElement = oelement.children(0).children(0)
这样的好处是简单,但坏处是:如何读取以及节点值究竟是什么含意这些信息,不太好抽取出来放到外面,作为灵活配置的文件。
因为它属于一个Childnodes一个Childnodes这么遍历的,无法灵活设定深度以及含义。
所以,采用了C#编写了一个专门的正则表达式处理组件HTMLParser.DLL。
它有一个接口方法ParserFile:
/* * 方法名:ParseFile * 所属类别: * 方法功能:传入参数是一个文件路径名,从文件中得到 要处理的内容流,然后用正则表达式分析 * 处理过程: 1:从文件中拿到正文HTML流; 2:正则表达式处理 3:得到一系列的Groups 4:根据Groups得到一系列的数据条目,拼出XML 5:将这个XML落地保存 * 返回值: 成功创建返回落地XML文件的路径名 否则返回空字符串 * 参数说明: strRegularExpression:正则表达式 strHTMLFilePath:HTML文件路径 strPortalName:门户的汉语拼音 strReceiveDate:该单下载的日期 strHandlerPeriod:该单下载的时间段 strBoardType:该单的类型 */ public String ParseFile(。。。。。 |
比如,举个简单的例子,河南的门户可以用这样的正则表达式解析:
<。。。。 |
我们用这种C#代码遍历MacthCollection,即可得到Named Groups(这种特性只有dotNet支持):
......... |
最后会得到像这样的XML数据:
。。。。。。。。 |
组件HTMLParser会把它命名为%原来的HTML文件名%.result.xml,还存储在同一个目录下。
3.2.解析程序
解析程序的细节被包裹在
Crawler.Parser
这个C#组件接口中,让它来分析HTML网页。
使用它的好处是:
l 逻辑独立,便于调试;
l C#的正则表达式支持Group特性,非常强大,这样我们可以兼容各种电信网通移动联通的不同样式页面,而且写这种分析网页代码量也少。
3.3.生成数据XML文件
解析之后,产品的各项参数按照配置文件中指定的格式输出。
在XML文件中要指定以下元素定义:
u .......
便于后续程序明白这些数据来源于哪里,要送到哪里。
3.4.通知数据自动存储层处理落地XML
XML文件落地后,需要用MSMQ消息队列来通知数据自动存储服务有新XML文件要处理了。
4 数据自动存储层-Spider.Saver
摘要:本章节简单介绍了Spider.Saver层如何解析落地XML文件,并生成SQL语句,同时插入数据库记录。
4.1. XSLT背景知识
假如说我们的业务数据XML类似于:
- .... |
那么我用如下的XSLT文件即可转换它:
。。。。 |
最后XSLT生成的SQL Script为:
。。。。 |
这样就自动生成了插入数据库的SQL脚本,这个XSLT是支持同一个Data根节点下包含多个Page的,它会相应地生成多个Insert语句。
4.2.XSLT转换线程
事先我们会起若干个XSLT转换线程,在I/O Complete Port上等候新XML文件的落地事件到来。
每个线程按照XML+XSLT的方式得到SQL脚本,然后用自身保持的数据库连接执行插入操作。
编写者:郑昀
Disclaimers:
Programmer’s Blog List: |
|
博客堂 |
|
博客园 |
|
Don Box's Blog |
Eric.Weblog() |
|
Blogs@asp.net |
|
本文档仅供参考。本文档所包含的信息代表了在发布之日,zhengyun对所讨论问题的当前看法,zhengyun不保证所给信息在发布之日以后的准确性。
用户应清楚本文档的准确性及其使用可能带来的全部风险。可以复制和传播本文档,但须遵守以下条款:
- 复制时不得修改原文,复制内容须包含所有页 ;
- 所有副本均须含有 zhengyun的版权声明以及所提供的其它声明 ;
- 不得以赢利为目的对本文档进行传播 。
Version | Date | Creator | Description |
1.0.0 .1 | 2004-9-06 | 郑昀 掌上灵通 | 草稿 |
|
|
|
|
摘要:
本文档详细介绍了网页数据采集系统的架构和运行机理。
第一章简单介绍了Spider的设计意图和模块构成。
第二章简单介绍了Spider.Crawler层如何抓取网页并落地。
第三章简单介绍了Spider.Parser层如何解析落地网页,并生成数据XML文件。
第四章简单介绍了Spider.Saver层如何解析落地XML文件,并生成SQL语句,同时插入数据库记录。
1概述
摘要:本章节简单介绍了Spider的设计意图和模块构成。
彩铃/炫铃数据采集子系统由以下几个模块构成:
n 网页抓取层
n 网页解析层
n 数据自动存储层
n 数据库
下面简单地对这四层做一个总体描述:
1.1.网页抓取层
本层负责从各地不同运营商的不同平台的数据门户抓取HTML页面,并存储在本地目录下。
存取的路径如图所示:
图1-1 存储文件夹树状结构
本层只负责抓取网页并落地,一旦落地成功,就发送MSMQ消息通知下一层去解析它。
1.2.网页解析层
网页解析层负责监听MSMQ消息队列中的网页落地消息。
一旦有消息到来,本层就得到了网页落地的路径以其他参数。
本层将会去读取该网页文件内容,利用C#的正则表达式处理模块得到业务数据。
得到数据之后,将把该数据保存为指定格式的XML文件,落地到相同目录下;然后同样用MSMQ消息通知下一层去处理。
1.3.数据自动存储层
数据自动存储层负责监听MSMQ消息队列中的网页解析消息。
一旦有消息到来,本层就得到了解析后的XML文件落地的路径以其他参数。
本层其实只是用XSLT对XML做Transform,得到最后要执行的SQL语句。
然后执行该SQL语句,将数据存储入对应的日统计表中,这些日统计表对应于移动门户的每日每个时段。比如,日统计表的命名规范可以是:
%移动运营商名称缩写% +
%日期% +
%时段% +
%类型%
。
1.4.数据库
数据库层提供数据服务。
目前采用的数据库是MSSqlServer。
架构图如下所示:
图 1-1 架构图
2 网页抓取层-Spider.Crawler
摘要:本章节简单介绍了Spider.Crawler层如何抓取网页并落地。
2.1.抓取背景知识
获取远端网页,可以用MSXML3.ServerXMLHTTP接口。用这个接口抓取网页有这么几个好处:
| ServerXMLHTTP优点 |
1 | Allows configuring timeouts when sending messages |
2 | The ServerXMLHTTP component does not impose any limits on the number of connections to a server |
3 | ServerXMLHTTP does not implement a cache |
表2-1 SXH优点
对于移动彩铃门户,网页速度是非常缓慢的,所以我们必须设置好请求网页的超时时间,以便重试。
SXH接口不限制连接数量,恰恰是我们需要的。我们可能开许多个并发连接到各个门户。
SXH接口没有实现缓存Cache,这样我们不用担心抓取到网页过时数据。
当然也有缺点:
| ServerXMLHTTP缺点 |
1 | ServerXMLHTTP does not support any auto-detection or discovery of proxy servers; you must explicitly specify the name of the proxy server using the proxycfg.exe utility. Can be configured with WinHTTP proxy config to access other machines directly (no proxy server). |
表2-2 SXH缺点
这样在异端代理服务器环境中,也许需要专门指定代理服务器才可以访问Internet。在实施中会是一个风险点。
2.2.并发抓取
我们可以设置配置文件,来动态要求网页抓取服务起多少个抓取线程,每个线程针对特定的门户抓取总排行榜。
2.3.网页落地
我们规定好网页落地的文件夹规则,抓取线程负责落地。如果文件夹不存在,那么就自动创建。
我们还要负责网页HTML文件的命名规则,比如TotalNo1.htm、TotalNo2.htm。
2.4.通知网页解析层处理落地文件
网页落地后,需要用MSMQ消息队列来通知网页解析服务有新文件要处理了。
用MSMQ消息队列作中间介质的优点是:
l 便于异步处理;
l 消息不会丢失;
l 将网页抓取速度和网页解析速度分离开来,免得形成性能瓶颈,因为一般解析速度是很快的,而下载网页速度却不一定,甚至于超时失败。
3 网页解析层-Spider.Parser
摘要:本章节简单介绍了Spider.Parser层如何解析落地网页,并生成数据XML文件。
3.1.解析背景知识
本来是想用IE WebControl解析网页得到特定网页中的特定数据:
Set oDocument = Form2.m_IE.Document
Set oelement = oDocument.Forms("searchdetail")
Set oListTableElement = oelement.children(0).children(0)
这样的好处是简单,但坏处是:如何读取以及节点值究竟是什么含意这些信息,不太好抽取出来放到外面,作为灵活配置的文件。
因为它属于一个Childnodes一个Childnodes这么遍历的,无法灵活设定深度以及含义。
所以,采用了C#编写了一个专门的正则表达式处理组件HTMLParser.DLL。
它有一个接口方法ParserFile:
/* * 方法名:ParseFile * 所属类别: * 方法功能:传入参数是一个文件路径名,从文件中得到 要处理的内容流,然后用正则表达式分析 * 处理过程: 1:从文件中拿到正文HTML流; 2:正则表达式处理 3:得到一系列的Groups 4:根据Groups得到一系列的数据条目,拼出XML 5:将这个XML落地保存 * 返回值: 成功创建返回落地XML文件的路径名 否则返回空字符串 * 参数说明: strRegularExpression:正则表达式 strHTMLFilePath:HTML文件路径 strPortalName:门户的汉语拼音 strReceiveDate:该单下载的日期 strHandlerPeriod:该单下载的时间段 strBoardType:该单的类型 */ public String ParseFile(。。。。。 |
比如,举个简单的例子,河南的门户可以用这样的正则表达式解析:
<。。。。 |
我们用这种C#代码遍历MacthCollection,即可得到Named Groups(这种特性只有dotNet支持):
......... |
最后会得到像这样的XML数据:
。。。。。。。。 |
组件HTMLParser会把它命名为%原来的HTML文件名%.result.xml,还存储在同一个目录下。
3.2.解析程序
解析程序的细节被包裹在
Crawler.Parser
这个C#组件接口中,让它来分析HTML网页。
使用它的好处是:
l 逻辑独立,便于调试;
l C#的正则表达式支持Group特性,非常强大,这样我们可以兼容各种电信网通移动联通的不同样式页面,而且写这种分析网页代码量也少。
3.3.生成数据XML文件
解析之后,产品的各项参数按照配置文件中指定的格式输出。
在XML文件中要指定以下元素定义:
u .......
便于后续程序明白这些数据来源于哪里,要送到哪里。
3.4.通知数据自动存储层处理落地XML
XML文件落地后,需要用MSMQ消息队列来通知数据自动存储服务有新XML文件要处理了。
4 数据自动存储层-Spider.Saver
摘要:本章节简单介绍了Spider.Saver层如何解析落地XML文件,并生成SQL语句,同时插入数据库记录。
4.1. XSLT背景知识
假如说我们的业务数据XML类似于:
- .... |
那么我用如下的XSLT文件即可转换它:
。。。。 |
最后XSLT生成的SQL Script为:
。。。。 |
这样就自动生成了插入数据库的SQL脚本,这个XSLT是支持同一个Data根节点下包含多个Page的,它会相应地生成多个Insert语句。
4.2.XSLT转换线程
事先我们会起若干个XSLT转换线程,在I/O Complete Port上等候新XML文件的落地事件到来。
每个线程按照XML+XSLT的方式得到SQL脚本,然后用自身保持的数据库连接执行插入操作。
编写者:郑昀
Disclaimers:
Programmer’s Blog List: |
|
博客堂 |
|
博客园 |
|
Don Box's Blog |
Eric.Weblog() |
|
Blogs@asp.net |
|
本文档仅供参考。本文档所包含的信息代表了在发布之日,zhengyun对所讨论问题的当前看法,zhengyun不保证所给信息在发布之日以后的准确性。
用户应清楚本文档的准确性及其使用可能带来的全部风险。可以复制和传播本文档,但须遵守以下条款:
- 复制时不得修改原文,复制内容须包含所有页 ;
- 所有副本均须含有 zhengyun的版权声明以及所提供的其它声明 ;
- 不得以赢利为目的对本文档进行传播 。
Version | Date | Creator | Description |
1.0.0 .1 | 2004-9-06 | 郑昀 掌上灵通 | 草稿 |
|
|
|
|
摘要:
本文档详细介绍了网页数据采集系统的架构和运行机理。
第一章简单介绍了Spider的设计意图和模块构成。
第二章简单介绍了Spider.Crawler层如何抓取网页并落地。
第三章简单介绍了Spider.Parser层如何解析落地网页,并生成数据XML文件。
第四章简单介绍了Spider.Saver层如何解析落地XML文件,并生成SQL语句,同时插入数据库记录。
1概述
摘要:本章节简单介绍了Spider的设计意图和模块构成。
彩铃/炫铃数据采集子系统由以下几个模块构成:
n 网页抓取层
n 网页解析层
n 数据自动存储层
n 数据库
下面简单地对这四层做一个总体描述:
1.1.网页抓取层
本层负责从各地不同运营商的不同平台的数据门户抓取HTML页面,并存储在本地目录下。
存取的路径如图所示:
图1-1 存储文件夹树状结构
本层只负责抓取网页并落地,一旦落地成功,就发送MSMQ消息通知下一层去解析它。
1.2.网页解析层
网页解析层负责监听MSMQ消息队列中的网页落地消息。
一旦有消息到来,本层就得到了网页落地的路径以其他参数。
本层将会去读取该网页文件内容,利用C#的正则表达式处理模块得到业务数据。
得到数据之后,将把该数据保存为指定格式的XML文件,落地到相同目录下;然后同样用MSMQ消息通知下一层去处理。
1.3.数据自动存储层
数据自动存储层负责监听MSMQ消息队列中的网页解析消息。
一旦有消息到来,本层就得到了解析后的XML文件落地的路径以其他参数。
本层其实只是用XSLT对XML做Transform,得到最后要执行的SQL语句。
然后执行该SQL语句,将数据存储入对应的日统计表中,这些日统计表对应于移动门户的每日每个时段。比如,日统计表的命名规范可以是:
%移动运营商名称缩写% +
%日期% +
%时段% +
%类型%
。
1.4.数据库
数据库层提供数据服务。
目前采用的数据库是MSSqlServer。
架构图如下所示:
图 1-1 架构图
2 网页抓取层-Spider.Crawler
摘要:本章节简单介绍了Spider.Crawler层如何抓取网页并落地。
2.1.抓取背景知识
获取远端网页,可以用MSXML3.ServerXMLHTTP接口。用这个接口抓取网页有这么几个好处:
| ServerXMLHTTP优点 |
1 | Allows configuring timeouts when sending messages |
2 | The ServerXMLHTTP component does not impose any limits on the number of connections to a server |
3 | ServerXMLHTTP does not implement a cache |
表2-1 SXH优点
对于移动彩铃门户,网页速度是非常缓慢的,所以我们必须设置好请求网页的超时时间,以便重试。
SXH接口不限制连接数量,恰恰是我们需要的。我们可能开许多个并发连接到各个门户。
SXH接口没有实现缓存Cache,这样我们不用担心抓取到网页过时数据。
当然也有缺点:
| ServerXMLHTTP缺点 |
1 | ServerXMLHTTP does not support any auto-detection or discovery of proxy servers; you must explicitly specify the name of the proxy server using the proxycfg.exe utility. Can be configured with WinHTTP proxy config to access other machines directly (no proxy server). |
表2-2 SXH缺点
这样在异端代理服务器环境中,也许需要专门指定代理服务器才可以访问Internet。在实施中会是一个风险点。
2.2.并发抓取
我们可以设置配置文件,来动态要求网页抓取服务起多少个抓取线程,每个线程针对特定的门户抓取总排行榜。
2.3.网页落地
我们规定好网页落地的文件夹规则,抓取线程负责落地。如果文件夹不存在,那么就自动创建。
我们还要负责网页HTML文件的命名规则,比如TotalNo1.htm、TotalNo2.htm。
2.4.通知网页解析层处理落地文件
网页落地后,需要用MSMQ消息队列来通知网页解析服务有新文件要处理了。
用MSMQ消息队列作中间介质的优点是:
l 便于异步处理;
l 消息不会丢失;
l 将网页抓取速度和网页解析速度分离开来,免得形成性能瓶颈,因为一般解析速度是很快的,而下载网页速度却不一定,甚至于超时失败。
3 网页解析层-Spider.Parser
摘要:本章节简单介绍了Spider.Parser层如何解析落地网页,并生成数据XML文件。
3.1.解析背景知识
本来是想用IE WebControl解析网页得到特定网页中的特定数据:
Set oDocument = Form2.m_IE.Document
Set oelement = oDocument.Forms("searchdetail")
Set oListTableElement = oelement.children(0).children(0)
这样的好处是简单,但坏处是:如何读取以及节点值究竟是什么含意这些信息,不太好抽取出来放到外面,作为灵活配置的文件。
因为它属于一个Childnodes一个Childnodes这么遍历的,无法灵活设定深度以及含义。
所以,采用了C#编写了一个专门的正则表达式处理组件HTMLParser.DLL。
它有一个接口方法ParserFile:
/* * 方法名:ParseFile * 所属类别: * 方法功能:传入参数是一个文件路径名,从文件中得到 要处理的内容流,然后用正则表达式分析 * 处理过程: 1:从文件中拿到正文HTML流; 2:正则表达式处理 3:得到一系列的Groups 4:根据Groups得到一系列的数据条目,拼出XML 5:将这个XML落地保存 * 返回值: 成功创建返回落地XML文件的路径名 否则返回空字符串 * 参数说明: strRegularExpression:正则表达式 strHTMLFilePath:HTML文件路径 strPortalName:门户的汉语拼音 strReceiveDate:该单下载的日期 strHandlerPeriod:该单下载的时间段 strBoardType:该单的类型 */ public String ParseFile(。。。。。 |
比如,举个简单的例子,河南的门户可以用这样的正则表达式解析:
<。。。。 |
我们用这种C#代码遍历MacthCollection,即可得到Named Groups(这种特性只有dotNet支持):
......... |
最后会得到像这样的XML数据:
。。。。。。。。 |
组件HTMLParser会把它命名为%原来的HTML文件名%.result.xml,还存储在同一个目录下。
3.2.解析程序
解析程序的细节被包裹在
Crawler.Parser
这个C#组件接口中,让它来分析HTML网页。
使用它的好处是:
l 逻辑独立,便于调试;
l C#的正则表达式支持Group特性,非常强大,这样我们可以兼容各种电信网通移动联通的不同样式页面,而且写这种分析网页代码量也少。
3.3.生成数据XML文件
解析之后,产品的各项参数按照配置文件中指定的格式输出。
在XML文件中要指定以下元素定义:
u .......
便于后续程序明白这些数据来源于哪里,要送到哪里。
3.4.通知数据自动存储层处理落地XML
XML文件落地后,需要用MSMQ消息队列来通知数据自动存储服务有新XML文件要处理了。
4 数据自动存储层-Spider.Saver
摘要:本章节简单介绍了Spider.Saver层如何解析落地XML文件,并生成SQL语句,同时插入数据库记录。
4.1. XSLT背景知识
假如说我们的业务数据XML类似于:
- .... |
那么我用如下的XSLT文件即可转换它:
。。。。 |
最后XSLT生成的SQL Script为:
。。。。 |
这样就自动生成了插入数据库的SQL脚本,这个XSLT是支持同一个Data根节点下包含多个Page的,它会相应地生成多个Insert语句。
4.2.XSLT转换线程
事先我们会起若干个XSLT转换线程,在I/O Complete Port上等候新XML文件的落地事件到来。
每个线程按照XML+XSLT的方式得到SQL脚本,然后用自身保持的数据库连接执行插入操作。
编写者:郑昀
Disclaimers:
Programmer’s Blog List: |
|
博客堂 |
|
博客园 |
|
Don Box's Blog |
Eric.Weblog() |
|
Blogs@asp.net |
|
本文档仅供参考。本文档所包含的信息代表了在发布之日,zhengyun对所讨论问题的当前看法,zhengyun不保证所给信息在发布之日以后的准确性。
用户应清楚本文档的准确性及其使用可能带来的全部风险。可以复制和传播本文档,但须遵守以下条款:
- 复制时不得修改原文,复制内容须包含所有页 ;
- 所有副本均须含有 zhengyun的版权声明以及所提供的其它声明 ;
- 不得以赢利为目的对本文档进行传播 。
Version | Date | Creator | Description |
1.0.0 .1 | 2004-9-06 | 郑昀 掌上灵通 | 草稿 |
|
|
|
|
摘要:
本文档详细介绍了网页数据采集系统的架构和运行机理。
第一章简单介绍了Spider的设计意图和模块构成。
第二章简单介绍了Spider.Crawler层如何抓取网页并落地。
第三章简单介绍了Spider.Parser层如何解析落地网页,并生成数据XML文件。
第四章简单介绍了Spider.Saver层如何解析落地XML文件,并生成SQL语句,同时插入数据库记录。
1概述
摘要:本章节简单介绍了Spider的设计意图和模块构成。
彩铃/炫铃数据采集子系统由以下几个模块构成:
n 网页抓取层
n 网页解析层
n 数据自动存储层
n 数据库
下面简单地对这四层做一个总体描述:
1.1.网页抓取层
本层负责从各地不同运营商的不同平台的数据门户抓取HTML页面,并存储在本地目录下。
存取的路径如图所示:
图1-1 存储文件夹树状结构
本层只负责抓取网页并落地,一旦落地成功,就发送MSMQ消息通知下一层去解析它。
1.2.网页解析层
网页解析层负责监听MSMQ消息队列中的网页落地消息。
一旦有消息到来,本层就得到了网页落地的路径以其他参数。
本层将会去读取该网页文件内容,利用C#的正则表达式处理模块得到业务数据。
得到数据之后,将把该数据保存为指定格式的XML文件,落地到相同目录下;然后同样用MSMQ消息通知下一层去处理。
1.3.数据自动存储层
数据自动存储层负责监听MSMQ消息队列中的网页解析消息。
一旦有消息到来,本层就得到了解析后的XML文件落地的路径以其他参数。
本层其实只是用XSLT对XML做Transform,得到最后要执行的SQL语句。
然后执行该SQL语句,将数据存储入对应的日统计表中,这些日统计表对应于移动门户的每日每个时段。比如,日统计表的命名规范可以是:
%移动运营商名称缩写% +
%日期% +
%时段% +
%类型%
。
1.4.数据库
数据库层提供数据服务。
目前采用的数据库是MSSqlServer。
架构图如下所示:
图 1-1 架构图
2 网页抓取层-Spider.Crawler
摘要:本章节简单介绍了Spider.Crawler层如何抓取网页并落地。
2.1.抓取背景知识
获取远端网页,可以用MSXML3.ServerXMLHTTP接口。用这个接口抓取网页有这么几个好处:
| ServerXMLHTTP优点 |
1 | Allows configuring timeouts when sending messages |
2 | The ServerXMLHTTP component does not impose any limits on the number of connections to a server |
3 | ServerXMLHTTP does not implement a cache |
表2-1 SXH优点
对于移动彩铃门户,网页速度是非常缓慢的,所以我们必须设置好请求网页的超时时间,以便重试。
SXH接口不限制连接数量,恰恰是我们需要的。我们可能开许多个并发连接到各个门户。
SXH接口没有实现缓存Cache,这样我们不用担心抓取到网页过时数据。
当然也有缺点:
| ServerXMLHTTP缺点 |
1 | ServerXMLHTTP does not support any auto-detection or discovery of proxy servers; you must explicitly specify the name of the proxy server using the proxycfg.exe utility. Can be configured with WinHTTP proxy config to access other machines directly (no proxy server). |
表2-2 SXH缺点
这样在异端代理服务器环境中,也许需要专门指定代理服务器才可以访问Internet。在实施中会是一个风险点。
2.2.并发抓取
我们可以设置配置文件,来动态要求网页抓取服务起多少个抓取线程,每个线程针对特定的门户抓取总排行榜。
2.3.网页落地
我们规定好网页落地的文件夹规则,抓取线程负责落地。如果文件夹不存在,那么就自动创建。
我们还要负责网页HTML文件的命名规则,比如TotalNo1.htm、TotalNo2.htm。
2.4.通知网页解析层处理落地文件
网页落地后,需要用MSMQ消息队列来通知网页解析服务有新文件要处理了。
用MSMQ消息队列作中间介质的优点是:
l 便于异步处理;
l 消息不会丢失;
l 将网页抓取速度和网页解析速度分离开来,免得形成性能瓶颈,因为一般解析速度是很快的,而下载网页速度却不一定,甚至于超时失败。
3 网页解析层-Spider.Parser
摘要:本章节简单介绍了Spider.Parser层如何解析落地网页,并生成数据XML文件。
3.1.解析背景知识
本来是想用IE WebControl解析网页得到特定网页中的特定数据:
Set oDocument = Form2.m_IE.Document
Set oelement = oDocument.Forms("searchdetail")
Set oListTableElement = oelement.children(0).children(0)
这样的好处是简单,但坏处是:如何读取以及节点值究竟是什么含意这些信息,不太好抽取出来放到外面,作为灵活配置的文件。
因为它属于一个Childnodes一个Childnodes这么遍历的,无法灵活设定深度以及含义。
所以,采用了C#编写了一个专门的正则表达式处理组件HTMLParser.DLL。
它有一个接口方法ParserFile:
/* * 方法名:ParseFile * 所属类别: * 方法功能:传入参数是一个文件路径名,从文件中得到 要处理的内容流,然后用正则表达式分析 * 处理过程: 1:从文件中拿到正文HTML流; 2:正则表达式处理 3:得到一系列的Groups 4:根据Groups得到一系列的数据条目,拼出XML 5:将这个XML落地保存 * 返回值: 成功创建返回落地XML文件的路径名 否则返回空字符串 * 参数说明: strRegularExpression:正则表达式 strHTMLFilePath:HTML文件路径 strPortalName:门户的汉语拼音 strReceiveDate:该单下载的日期 strHandlerPeriod:该单下载的时间段 strBoardType:该单的类型 */ public String ParseFile(。。。。。 |
比如,举个简单的例子,河南的门户可以用这样的正则表达式解析:
<。。。。 |
我们用这种C#代码遍历MacthCollection,即可得到Named Groups(这种特性只有dotNet支持):
......... |
最后会得到像这样的XML数据:
。。。。。。。。 |
组件HTMLParser会把它命名为%原来的HTML文件名%.result.xml,还存储在同一个目录下。
3.2.解析程序
解析程序的细节被包裹在
Crawler.Parser
这个C#组件接口中,让它来分析HTML网页。
使用它的好处是:
l 逻辑独立,便于调试;
l C#的正则表达式支持Group特性,非常强大,这样我们可以兼容各种电信网通移动联通的不同样式页面,而且写这种分析网页代码量也少。
3.3.生成数据XML文件
解析之后,产品的各项参数按照配置文件中指定的格式输出。
在XML文件中要指定以下元素定义:
u .......
便于后续程序明白这些数据来源于哪里,要送到哪里。
3.4.通知数据自动存储层处理落地XML
XML文件落地后,需要用MSMQ消息队列来通知数据自动存储服务有新XML文件要处理了。
4 数据自动存储层-Spider.Saver
摘要:本章节简单介绍了Spider.Saver层如何解析落地XML文件,并生成SQL语句,同时插入数据库记录。
4.1. XSLT背景知识
假如说我们的业务数据XML类似于:
- .... |
那么我用如下的XSLT文件即可转换它:
。。。。 |
最后XSLT生成的SQL Script为:
。。。。 |
这样就自动生成了插入数据库的SQL脚本,这个XSLT是支持同一个Data根节点下包含多个Page的,它会相应地生成多个Insert语句。
4.2.XSLT转换线程
事先我们会起若干个XSLT转换线程,在I/O Complete Port上等候新XML文件的落地事件到来。
每个线程按照XML+XSLT的方式得到SQL脚本,然后用自身保持的数据库连接执行插入操作。
编写者:郑昀
Disclaimers:
Programmer’s Blog List: |
|
博客堂 |
|
博客园 |
|
Don Box's Blog |
Eric.Weblog() |
|
Blogs@asp.net |
|
本文档仅供参考。本文档所包含的信息代表了在发布之日,zhengyun对所讨论问题的当前看法,zhengyun不保证所给信息在发布之日以后的准确性。
用户应清楚本文档的准确性及其使用可能带来的全部风险。可以复制和传播本文档,但须遵守以下条款:
- 复制时不得修改原文,复制内容须包含所有页 ;
- 所有副本均须含有 zhengyun的版权声明以及所提供的其它声明 ;
- 不得以赢利为目的对本文档进行传播 。
Version | Date | Creator | Description |
1.0.0 .1 | 2004-9-06 | 郑昀 掌上灵通 | 草稿 |
|
|
|
|
摘要:
本文档详细介绍了网页数据采集系统的架构和运行机理。
第一章简单介绍了Spider的设计意图和模块构成。
第二章简单介绍了Spider.Crawler层如何抓取网页并落地。
第三章简单介绍了Spider.Parser层如何解析落地网页,并生成数据XML文件。
第四章简单介绍了Spider.Saver层如何解析落地XML文件,并生成SQL语句,同时插入数据库记录。
1概述
摘要:本章节简单介绍了Spider的设计意图和模块构成。
彩铃/炫铃数据采集子系统由以下几个模块构成:
n 网页抓取层
n 网页解析层
n 数据自动存储层
n 数据库
下面简单地对这四层做一个总体描述:
1.1.网页抓取层
本层负责从各地不同运营商的不同平台的数据门户抓取HTML页面,并存储在本地目录下。
存取的路径如图所示:
图1-1 存储文件夹树状结构
本层只负责抓取网页并落地,一旦落地成功,就发送MSMQ消息通知下一层去解析它。
1.2.网页解析层
网页解析层负责监听MSMQ消息队列中的网页落地消息。
一旦有消息到来,本层就得到了网页落地的路径以其他参数。
本层将会去读取该网页文件内容,利用C#的正则表达式处理模块得到业务数据。
得到数据之后,将把该数据保存为指定格式的XML文件,落地到相同目录下;然后同样用MSMQ消息通知下一层去处理。
1.3.数据自动存储层
数据自动存储层负责监听MSMQ消息队列中的网页解析消息。
一旦有消息到来,本层就得到了解析后的XML文件落地的路径以其他参数。
本层其实只是用XSLT对XML做Transform,得到最后要执行的SQL语句。
然后执行该SQL语句,将数据存储入对应的日统计表中,这些日统计表对应于移动门户的每日每个时段。比如,日统计表的命名规范可以是:
%移动运营商名称缩写% +
%日期% +
%时段% +
%类型%
。
1.4.数据库
数据库层提供数据服务。
目前采用的数据库是MSSqlServer。
架构图如下所示:
图 1-1 架构图
2 网页抓取层-Spider.Crawler
摘要:本章节简单介绍了Spider.Crawler层如何抓取网页并落地。
2.1.抓取背景知识
获取远端网页,可以用MSXML3.ServerXMLHTTP接口。用这个接口抓取网页有这么几个好处:
| ServerXMLHTTP优点 |
1 | Allows configuring timeouts when sending messages |
2 | The ServerXMLHTTP component does not impose any limits on the number of connections to a server |
3 | ServerXMLHTTP does not implement a cache |
表2-1 SXH优点
对于移动彩铃门户,网页速度是非常缓慢的,所以我们必须设置好请求网页的超时时间,以便重试。
SXH接口不限制连接数量,恰恰是我们需要的。我们可能开许多个并发连接到各个门户。
SXH接口没有实现缓存Cache,这样我们不用担心抓取到网页过时数据。
当然也有缺点:
| ServerXMLHTTP缺点 |
1 | ServerXMLHTTP does not support any auto-detection or discovery of proxy servers; you must explicitly specify the name of the proxy server using the proxycfg.exe utility. Can be configured with WinHTTP proxy config to access other machines directly (no proxy server). |
表2-2 SXH缺点
这样在异端代理服务器环境中,也许需要专门指定代理服务器才可以访问Internet。在实施中会是一个风险点。
2.2.并发抓取
我们可以设置配置文件,来动态要求网页抓取服务起多少个抓取线程,每个线程针对特定的门户抓取总排行榜。
2.3.网页落地
我们规定好网页落地的文件夹规则,抓取线程负责落地。如果文件夹不存在,那么就自动创建。
我们还要负责网页HTML文件的命名规则,比如TotalNo1.htm、TotalNo2.htm。
2.4.通知网页解析层处理落地文件
网页落地后,需要用MSMQ消息队列来通知网页解析服务有新文件要处理了。
用MSMQ消息队列作中间介质的优点是:
l 便于异步处理;
l 消息不会丢失;
l 将网页抓取速度和网页解析速度分离开来,免得形成性能瓶颈,因为一般解析速度是很快的,而下载网页速度却不一定,甚至于超时失败。
3 网页解析层-Spider.Parser
摘要:本章节简单介绍了Spider.Parser层如何解析落地网页,并生成数据XML文件。
3.1.解析背景知识
本来是想用IE WebControl解析网页得到特定网页中的特定数据:
Set oDocument = Form2.m_IE.Document
Set oelement = oDocument.Forms("searchdetail")
Set oListTableElement = oelement.children(0).children(0)
这样的好处是简单,但坏处是:如何读取以及节点值究竟是什么含意这些信息,不太好抽取出来放到外面,作为灵活配置的文件。
因为它属于一个Childnodes一个Childnodes这么遍历的,无法灵活设定深度以及含义。
所以,采用了C#编写了一个专门的正则表达式处理组件HTMLParser.DLL。
它有一个接口方法ParserFile:
/* * 方法名:ParseFile * 所属类别: * 方法功能:传入参数是一个文件路径名,从文件中得到 要处理的内容流,然后用正则表达式分析 * 处理过程: 1:从文件中拿到正文HTML流; 2:正则表达式处理 3:得到一系列的Groups 4:根据Groups得到一系列的数据条目,拼出XML 5:将这个XML落地保存 * 返回值: 成功创建返回落地XML文件的路径名 否则返回空字符串 * 参数说明: strRegularExpression:正则表达式 strHTMLFilePath:HTML文件路径 strPortalName:门户的汉语拼音 strReceiveDate:该单下载的日期 strHandlerPeriod:该单下载的时间段 strBoardType:该单的类型 */ public String ParseFile(。。。。。 |
比如,举个简单的例子,河南的门户可以用这样的正则表达式解析:
<。。。。 |
我们用这种C#代码遍历MacthCollection,即可得到Named Groups(这种特性只有dotNet支持):
......... |
最后会得到像这样的XML数据:
。。。。。。。。 |
组件HTMLParser会把它命名为%原来的HTML文件名%.result.xml,还存储在同一个目录下。
3.2.解析程序
解析程序的细节被包裹在
Crawler.Parser
这个C#组件接口中,让它来分析HTML网页。
使用它的好处是:
l 逻辑独立,便于调试;
l C#的正则表达式支持Group特性,非常强大,这样我们可以兼容各种电信网通移动联通的不同样式页面,而且写这种分析网页代码量也少。
3.3.生成数据XML文件
解析之后,产品的各项参数按照配置文件中指定的格式输出。
在XML文件中要指定以下元素定义:
u .......
便于后续程序明白这些数据来源于哪里,要送到哪里。
3.4.通知数据自动存储层处理落地XML
XML文件落地后,需要用MSMQ消息队列来通知数据自动存储服务有新XML文件要处理了。
4 数据自动存储层-Spider.Saver
摘要:本章节简单介绍了Spider.Saver层如何解析落地XML文件,并生成SQL语句,同时插入数据库记录。
4.1. XSLT背景知识
假如说我们的业务数据XML类似于:
- .... |
那么我用如下的XSLT文件即可转换它:
。。。。 |
最后XSLT生成的SQL Script为:
。。。。 |
这样就自动生成了插入数据库的SQL脚本,这个XSLT是支持同一个Data根节点下包含多个Page的,它会相应地生成多个Insert语句。
4.2.XSLT转换线程
事先我们会起若干个XSLT转换线程,在I/O Complete Port上等候新XML文件的落地事件到来。
每个线程按照XML+XSLT的方式得到SQL脚本,然后用自身保持的数据库连接执行插入操作。
编写者:郑昀
Disclaimers:
Programmer’s Blog List: |
|
博客堂 |
|
博客园 |
|
Don Box's Blog |
Eric.Weblog() |
|
Blogs@asp.net |
|
本文档仅供参考。本文档所包含的信息代表了在发布之日,zhengyun对所讨论问题的当前看法,zhengyun不保证所给信息在发布之日以后的准确性。
用户应清楚本文档的准确性及其使用可能带来的全部风险。可以复制和传播本文档,但须遵守以下条款:
- 复制时不得修改原文,复制内容须包含所有页 ;
- 所有副本均须含有 zhengyun的版权声明以及所提供的其它声明 ;
- 不得以赢利为目的对本文档进行传播 。
Version | Date | Creator | Description |
1.0.0 .1 | 2004-9-06 | 郑昀 掌上灵通 | 草稿 |
|
|
|
|
摘要:
本文档详细介绍了网页数据采集系统的架构和运行机理。
第一章简单介绍了Spider的设计意图和模块构成。
第二章简单介绍了Spider.Crawler层如何抓取网页并落地。
第三章简单介绍了Spider.Parser层如何解析落地网页,并生成数据XML文件。
第四章简单介绍了Spider.Saver层如何解析落地XML文件,并生成SQL语句,同时插入数据库记录。
1概述
摘要:本章节简单介绍了Spider的设计意图和模块构成。
彩铃/炫铃数据采集子系统由以下几个模块构成:
n 网页抓取层
n 网页解析层
n 数据自动存储层
n 数据库
下面简单地对这四层做一个总体描述:
1.1.网页抓取层
本层负责从各地不同运营商的不同平台的数据门户抓取HTML页面,并存储在本地目录下。
存取的路径如图所示:
图1-1 存储文件夹树状结构
本层只负责抓取网页并落地,一旦落地成功,就发送MSMQ消息通知下一层去解析它。
1.2.网页解析层
网页解析层负责监听MSMQ消息队列中的网页落地消息。
一旦有消息到来,本层就得到了网页落地的路径以其他参数。
本层将会去读取该网页文件内容,利用C#的正则表达式处理模块得到业务数据。
得到数据之后,将把该数据保存为指定格式的XML文件,落地到相同目录下;然后同样用MSMQ消息通知下一层去处理。
1.3.数据自动存储层
数据自动存储层负责监听MSMQ消息队列中的网页解析消息。
一旦有消息到来,本层就得到了解析后的XML文件落地的路径以其他参数。
本层其实只是用XSLT对XML做Transform,得到最后要执行的SQL语句。
然后执行该SQL语句,将数据存储入对应的日统计表中,这些日统计表对应于移动门户的每日每个时段。比如,日统计表的命名规范可以是:
%移动运营商名称缩写% +
%日期% +
%时段% +
%类型%
。
1.4.数据库
数据库层提供数据服务。
目前采用的数据库是MSSqlServer。
架构图如下所示:
图 1-1 架构图
2 网页抓取层-Spider.Crawler
摘要:本章节简单介绍了Spider.Crawler层如何抓取网页并落地。
2.1.抓取背景知识
获取远端网页,可以用MSXML3.ServerXMLHTTP接口。用这个接口抓取网页有这么几个好处:
| ServerXMLHTTP优点 |
1 | Allows configuring timeouts when sending messages |
2 | The ServerXMLHTTP component does not impose any limits on the number of connections to a server |
3 | ServerXMLHTTP does not implement a cache |
表2-1 SXH优点
对于移动彩铃门户,网页速度是非常缓慢的,所以我们必须设置好请求网页的超时时间,以便重试。
SXH接口不限制连接数量,恰恰是我们需要的。我们可能开许多个并发连接到各个门户。
SXH接口没有实现缓存Cache,这样我们不用担心抓取到网页过时数据。
当然也有缺点:
| ServerXMLHTTP缺点 |
1 | ServerXMLHTTP does not support any auto-detection or discovery of proxy servers; you must explicitly specify the name of the proxy server using the proxycfg.exe utility. Can be configured with WinHTTP proxy config to access other machines directly (no proxy server). |
表2-2 SXH缺点
这样在异端代理服务器环境中,也许需要专门指定代理服务器才可以访问Internet。在实施中会是一个风险点。
2.2.并发抓取
我们可以设置配置文件,来动态要求网页抓取服务起多少个抓取线程,每个线程针对特定的门户抓取总排行榜。
2.3.网页落地
我们规定好网页落地的文件夹规则,抓取线程负责落地。如果文件夹不存在,那么就自动创建。
我们还要负责网页HTML文件的命名规则,比如TotalNo1.htm、TotalNo2.htm。
2.4.通知网页解析层处理落地文件
网页落地后,需要用MSMQ消息队列来通知网页解析服务有新文件要处理了。
用MSMQ消息队列作中间介质的优点是:
l 便于异步处理;
l 消息不会丢失;
l 将网页抓取速度和网页解析速度分离开来,免得形成性能瓶颈,因为一般解析速度是很快的,而下载网页速度却不一定,甚至于超时失败。
3 网页解析层-Spider.Parser
摘要:本章节简单介绍了Spider.Parser层如何解析落地网页,并生成数据XML文件。
3.1.解析背景知识
本来是想用IE WebControl解析网页得到特定网页中的特定数据:
Set oDocument = Form2.m_IE.Document
Set oelement = oDocument.Forms("searchdetail")
Set oListTableElement = oelement.children(0).children(0)
这样的好处是简单,但坏处是:如何读取以及节点值究竟是什么含意这些信息,不太好抽取出来放到外面,作为灵活配置的文件。
因为它属于一个Childnodes一个Childnodes这么遍历的,无法灵活设定深度以及含义。
所以,采用了C#编写了一个专门的正则表达式处理组件HTMLParser.DLL。
它有一个接口方法ParserFile:
/* * 方法名:ParseFile * 所属类别: * 方法功能:传入参数是一个文件路径名,从文件中得到 要处理的内容流,然后用正则表达式分析 * 处理过程: 1:从文件中拿到正文HTML流; 2:正则表达式处理 3:得到一系列的Groups 4:根据Groups得到一系列的数据条目,拼出XML 5:将这个XML落地保存 * 返回值: 成功创建返回落地XML文件的路径名 否则返回空字符串 * 参数说明: strRegularExpression:正则表达式 strHTMLFilePath:HTML文件路径 strPortalName:门户的汉语拼音 strReceiveDate:该单下载的日期 strHandlerPeriod:该单下载的时间段 strBoardType:该单的类型 */ public String ParseFile(。。。。。 |
比如,举个简单的例子,河南的门户可以用这样的正则表达式解析:
<。。。。 |
我们用这种C#代码遍历MacthCollection,即可得到Named Groups(这种特性只有dotNet支持):
......... |
最后会得到像这样的XML数据:
。。。。。。。。 |
组件HTMLParser会把它命名为%原来的HTML文件名%.result.xml,还存储在同一个目录下。
3.2.解析程序
解析程序的细节被包裹在
Crawler.Parser
这个C#组件接口中,让它来分析HTML网页。
使用它的好处是:
l 逻辑独立,便于调试;
l C#的正则表达式支持Group特性,非常强大,这样我们可以兼容各种电信网通移动联通的不同样式页面,而且写这种分析网页代码量也少。
3.3.生成数据XML文件
解析之后,产品的各项参数按照配置文件中指定的格式输出。
在XML文件中要指定以下元素定义:
u .......
便于后续程序明白这些数据来源于哪里,要送到哪里。
3.4.通知数据自动存储层处理落地XML
XML文件落地后,需要用MSMQ消息队列来通知数据自动存储服务有新XML文件要处理了。
4 数据自动存储层-Spider.Saver
摘要:本章节简单介绍了Spider.Saver层如何解析落地XML文件,并生成SQL语句,同时插入数据库记录。
4.1. XSLT背景知识
假如说我们的业务数据XML类似于:
- .... |
那么我用如下的XSLT文件即可转换它:
。。。。 |
最后XSLT生成的SQL Script为:
。。。。 |
这样就自动生成了插入数据库的SQL脚本,这个XSLT是支持同一个Data根节点下包含多个Page的,它会相应地生成多个Insert语句。
4.2.XSLT转换线程
事先我们会起若干个XSLT转换线程,在I/O Complete Port上等候新XML文件的落地事件到来。
每个线程按照XML+XSLT的方式得到SQL脚本,然后用自身保持的数据库连接执行插入操作。
编写者:郑昀
Disclaimers:
Programmer’s Blog List: |
|
博客堂 |
|
博客园 |
|
Don Box's Blog |
Eric.Weblog() |
|
Blogs@asp.net |
|
本文档仅供参考。本文档所包含的信息代表了在发布之日,zhengyun对所讨论问题的当前看法,zhengyun不保证所给信息在发布之日以后的准确性。
用户应清楚本文档的准确性及其使用可能带来的全部风险。可以复制和传播本文档,但须遵守以下条款:
- 复制时不得修改原文,复制内容须包含所有页 ;
- 所有副本均须含有 zhengyun的版权声明以及所提供的其它声明 ;
- 不得以赢利为目的对本文档进行传播 。
Version | Date | Creator | Description |
1.0.0 .1 | 2004-9-06 | 郑昀 掌上灵通 | 草稿 |
|
|
|
|
摘要:
本文档详细介绍了网页数据采集系统的架构和运行机理。
第一章简单介绍了Spider的设计意图和模块构成。
第二章简单介绍了Spider.Crawler层如何抓取网页并落地。
第三章简单介绍了Spider.Parser层如何解析落地网页,并生成数据XML文件。
第四章简单介绍了Spider.Saver层如何解析落地XML文件,并生成SQL语句,同时插入数据库记录。
1概述
摘要:本章节简单介绍了Spider的设计意图和模块构成。
彩铃/炫铃数据采集子系统由以下几个模块构成:
n 网页抓取层
n 网页解析层
n 数据自动存储层
n 数据库
下面简单地对这四层做一个总体描述:
1.1.网页抓取层
本层负责从各地不同运营商的不同平台的数据门户抓取HTML页面,并存储在本地目录下。
存取的路径如图所示:
图1-1 存储文件夹树状结构
本层只负责抓取网页并落地,一旦落地成功,就发送MSMQ消息通知下一层去解析它。
1.2.网页解析层
网页解析层负责监听MSMQ消息队列中的网页落地消息。
一旦有消息到来,本层就得到了网页落地的路径以其他参数。
本层将会去读取该网页文件内容,利用C#的正则表达式处理模块得到业务数据。
得到数据之后,将把该数据保存为指定格式的XML文件,落地到相同目录下;然后同样用MSMQ消息通知下一层去处理。
1.3.数据自动存储层
数据自动存储层负责监听MSMQ消息队列中的网页解析消息。
一旦有消息到来,本层就得到了解析后的XML文件落地的路径以其他参数。
本层其实只是用XSLT对XML做Transform,得到最后要执行的SQL语句。
然后执行该SQL语句,将数据存储入对应的日统计表中,这些日统计表对应于移动门户的每日每个时段。比如,日统计表的命名规范可以是:
%移动运营商名称缩写% +
%日期% +
%时段% +
%类型%
。
1.4.数据库
数据库层提供数据服务。
目前采用的数据库是MSSqlServer。
架构图如下所示:
图 1-1 架构图
2 网页抓取层-Spider.Crawler
摘要:本章节简单介绍了Spider.Crawler层如何抓取网页并落地。
2.1.抓取背景知识
获取远端网页,可以用MSXML3.ServerXMLHTTP接口。用这个接口抓取网页有这么几个好处:
| ServerXMLHTTP优点 |
1 | Allows configuring timeouts when sending messages |
2 | The ServerXMLHTTP component does not impose any limits on the number of connections to a server |
3 | ServerXMLHTTP does not implement a cache |
表2-1 SXH优点
对于移动彩铃门户,网页速度是非常缓慢的,所以我们必须设置好请求网页的超时时间,以便重试。
SXH接口不限制连接数量,恰恰是我们需要的。我们可能开许多个并发连接到各个门户。
SXH接口没有实现缓存Cache,这样我们不用担心抓取到网页过时数据。
当然也有缺点:
| ServerXMLHTTP缺点 |
1 | ServerXMLHTTP does not support any auto-detection or discovery of proxy servers; you must explicitly specify the name of the proxy server using the proxycfg.exe utility. Can be configured with WinHTTP proxy config to access other machines directly (no proxy server). |
表2-2 SXH缺点
这样在异端代理服务器环境中,也许需要专门指定代理服务器才可以访问Internet。在实施中会是一个风险点。
2.2.并发抓取
我们可以设置配置文件,来动态要求网页抓取服务起多少个抓取线程,每个线程针对特定的门户抓取总排行榜。
2.3.网页落地
我们规定好网页落地的文件夹规则,抓取线程负责落地。如果文件夹不存在,那么就自动创建。
我们还要负责网页HTML文件的命名规则,比如TotalNo1.htm、TotalNo2.htm。
2.4.通知网页解析层处理落地文件
网页落地后,需要用MSMQ消息队列来通知网页解析服务有新文件要处理了。
用MSMQ消息队列作中间介质的优点是:
l 便于异步处理;
l 消息不会丢失;
l 将网页抓取速度和网页解析速度分离开来,免得形成性能瓶颈,因为一般解析速度是很快的,而下载网页速度却不一定,甚至于超时失败。
3 网页解析层-Spider.Parser
摘要:本章节简单介绍了Spider.Parser层如何解析落地网页,并生成数据XML文件。
3.1.解析背景知识
本来是想用IE WebControl解析网页得到特定网页中的特定数据:
Set oDocument = Form2.m_IE.Document
Set oelement = oDocument.Forms("searchdetail")
Set oListTableElement = oelement.children(0).children(0)
这样的好处是简单,但坏处是:如何读取以及节点值究竟是什么含意这些信息,不太好抽取出来放到外面,作为灵活配置的文件。
因为它属于一个Childnodes一个Childnodes这么遍历的,无法灵活设定深度以及含义。
所以,采用了C#编写了一个专门的正则表达式处理组件HTMLParser.DLL。
它有一个接口方法ParserFile:
/* * 方法名:ParseFile * 所属类别: * 方法功能:传入参数是一个文件路径名,从文件中得到 要处理的内容流,然后用正则表达式分析 * 处理过程: 1:从文件中拿到正文HTML流; 2:正则表达式处理 3:得到一系列的Groups 4:根据Groups得到一系列的数据条目,拼出XML 5:将这个XML落地保存 * 返回值: 成功创建返回落地XML文件的路径名 否则返回空字符串 * 参数说明: strRegularExpression:正则表达式 strHTMLFilePath:HTML文件路径 strPortalName:门户的汉语拼音 strReceiveDate:该单下载的日期 strHandlerPeriod:该单下载的时间段 strBoardType:该单的类型 */ public String ParseFile(。。。。。 |
比如,举个简单的例子,河南的门户可以用这样的正则表达式解析:
<。。。。 |
我们用这种C#代码遍历MacthCollection,即可得到Named Groups(这种特性只有dotNet支持):
......... |
最后会得到像这样的XML数据:
。。。。。。。。 |
组件HTMLParser会把它命名为%原来的HTML文件名%.result.xml,还存储在同一个目录下。
3.2.解析程序
解析程序的细节被包裹在
Crawler.Parser
这个C#组件接口中,让它来分析HTML网页。
使用它的好处是:
l 逻辑独立,便于调试;
l C#的正则表达式支持Group特性,非常强大,这样我们可以兼容各种电信网通移动联通的不同样式页面,而且写这种分析网页代码量也少。
3.3.生成数据XML文件
解析之后,产品的各项参数按照配置文件中指定的格式输出。
在XML文件中要指定以下元素定义:
u .......
便于后续程序明白这些数据来源于哪里,要送到哪里。
3.4.通知数据自动存储层处理落地XML
XML文件落地后,需要用MSMQ消息队列来通知数据自动存储服务有新XML文件要处理了。
4 数据自动存储层-Spider.Saver
摘要:本章节简单介绍了Spider.Saver层如何解析落地XML文件,并生成SQL语句,同时插入数据库记录。
4.1. XSLT背景知识
假如说我们的业务数据XML类似于:
- .... |
那么我用如下的XSLT文件即可转换它:
。。。。 |
最后XSLT生成的SQL Script为:
。。。。 |
这样就自动生成了插入数据库的SQL脚本,这个XSLT是支持同一个Data根节点下包含多个Page的,它会相应地生成多个Insert语句。
4.2.XSLT转换线程
事先我们会起若干个XSLT转换线程,在I/O Complete Port上等候新XML文件的落地事件到来。
每个线程按照XML+XSLT的方式得到SQL脚本,然后用自身保持的数据库连接执行插入操作。
编写者:郑昀
Disclaimers:
Programmer’s Blog List: |
|
博客堂 |
|
博客园 |
|
Don Box's Blog |
Eric.Weblog() |
|
Blogs@asp.net |
|
本文档仅供参考。本文档所包含的信息代表了在发布之日,zhengyun对所讨论问题的当前看法,zhengyun不保证所给信息在发布之日以后的准确性。
用户应清楚本文档的准确性及其使用可能带来的全部风险。可以复制和传播本文档,但须遵守以下条款:
- 复制时不得修改原文,复制内容须包含所有页 ;
- 所有副本均须含有 zhengyun的版权声明以及所提供的其它声明 ;
- 不得以赢利为目的对本文档进行传播 。
Version | Date | Creator | Description |
1.0.0 .1 | 2004-9-06 | 郑昀 掌上灵通 | 草稿 |
|
|
|
|
摘要:
本文档详细介绍了网页数据采集系统的架构和运行机理。
第一章简单介绍了Spider的设计意图和模块构成。
第二章简单介绍了Spider.Crawler层如何抓取网页并落地。
第三章简单介绍了Spider.Parser层如何解析落地网页,并生成数据XML文件。
第四章简单介绍了Spider.Saver层如何解析落地XML文件,并生成SQL语句,同时插入数据库记录。
1概述
摘要:本章节简单介绍了Spider的设计意图和模块构成。
彩铃/炫铃数据采集子系统由以下几个模块构成:
n 网页抓取层
n 网页解析层
n 数据自动存储层
n 数据库
下面简单地对这四层做一个总体描述:
1.1.网页抓取层
本层负责从各地不同运营商的不同平台的数据门户抓取HTML页面,并存储在本地目录下。
存取的路径如图所示:
图1-1 存储文件夹树状结构
本层只负责抓取网页并落地,一旦落地成功,就发送MSMQ消息通知下一层去解析它。
1.2.网页解析层
网页解析层负责监听MSMQ消息队列中的网页落地消息。
一旦有消息到来,本层就得到了网页落地的路径以其他参数。
本层将会去读取该网页文件内容,利用C#的正则表达式处理模块得到业务数据。
得到数据之后,将把该数据保存为指定格式的XML文件,落地到相同目录下;然后同样用MSMQ消息通知下一层去处理。
1.3.数据自动存储层
数据自动存储层负责监听MSMQ消息队列中的网页解析消息。
一旦有消息到来,本层就得到了解析后的XML文件落地的路径以其他参数。
本层其实只是用XSLT对XML做Transform,得到最后要执行的SQL语句。
然后执行该SQL语句,将数据存储入对应的日统计表中,这些日统计表对应于移动门户的每日每个时段。比如,日统计表的命名规范可以是:
%移动运营商名称缩写% +
%日期% +
%时段% +
%类型%
。
1.4.数据库
数据库层提供数据服务。
目前采用的数据库是MSSqlServer。
架构图如下所示:
图 1-1 架构图
2 网页抓取层-Spider.Crawler
摘要:本章节简单介绍了Spider.Crawler层如何抓取网页并落地。
2.1.抓取背景知识
获取远端网页,可以用MSXML3.ServerXMLHTTP接口。用这个接口抓取网页有这么几个好处:
| ServerXMLHTTP优点 |
1 | Allows configuring timeouts when sending messages |
2 | The ServerXMLHTTP component does not impose any limits on the number of connections to a server |
3 | ServerXMLHTTP does not implement a cache |
表2-1 SXH优点
对于移动彩铃门户,网页速度是非常缓慢的,所以我们必须设置好请求网页的超时时间,以便重试。
SXH接口不限制连接数量,恰恰是我们需要的。我们可能开许多个并发连接到各个门户。
SXH接口没有实现缓存Cache,这样我们不用担心抓取到网页过时数据。
当然也有缺点:
| ServerXMLHTTP缺点 |
1 | ServerXMLHTTP does not support any auto-detection or discovery of proxy servers; you must explicitly specify the name of the proxy server using the proxycfg.exe utility. Can be configured with WinHTTP proxy config to access other machines directly (no proxy server). |
表2-2 SXH缺点
这样在异端代理服务器环境中,也许需要专门指定代理服务器才可以访问Internet。在实施中会是一个风险点。
2.2.并发抓取
我们可以设置配置文件,来动态要求网页抓取服务起多少个抓取线程,每个线程针对特定的门户抓取总排行榜。
2.3.网页落地
我们规定好网页落地的文件夹规则,抓取线程负责落地。如果文件夹不存在,那么就自动创建。
我们还要负责网页HTML文件的命名规则,比如TotalNo1.htm、TotalNo2.htm。
2.4.通知网页解析层处理落地文件
网页落地后,需要用MSMQ消息队列来通知网页解析服务有新文件要处理了。
用MSMQ消息队列作中间介质的优点是:
l 便于异步处理;
l 消息不会丢失;
l 将网页抓取速度和网页解析速度分离开来,免得形成性能瓶颈,因为一般解析速度是很快的,而下载网页速度却不一定,甚至于超时失败。
3 网页解析层-Spider.Parser
摘要:本章节简单介绍了Spider.Parser层如何解析落地网页,并生成数据XML文件。
3.1.解析背景知识
本来是想用IE WebControl解析网页得到特定网页中的特定数据:
Set oDocument = Form2.m_IE.Document
Set oelement = oDocument.Forms("searchdetail")
Set oListTableElement = oelement.children(0).children(0)
这样的好处是简单,但坏处是:如何读取以及节点值究竟是什么含意这些信息,不太好抽取出来放到外面,作为灵活配置的文件。
因为它属于一个Childnodes一个Childnodes这么遍历的,无法灵活设定深度以及含义。
所以,采用了C#编写了一个专门的正则表达式处理组件HTMLParser.DLL。
它有一个接口方法ParserFile:
/* * 方法名:ParseFile * 所属类别: * 方法功能:传入参数是一个文件路径名,从文件中得到 要处理的内容流,然后用正则表达式分析 * 处理过程: 1:从文件中拿到正文HTML流; 2:正则表达式处理 3:得到一系列的Groups 4:根据Groups得到一系列的数据条目,拼出XML 5:将这个XML落地保存 * 返回值: 成功创建返回落地XML文件的路径名 否则返回空字符串 * 参数说明: strRegularExpression:正则表达式 strHTMLFilePath:HTML文件路径 strPortalName:门户的汉语拼音 strReceiveDate:该单下载的日期 strHandlerPeriod:该单下载的时间段 strBoardType:该单的类型 */ public String ParseFile(。。。。。 |
比如,举个简单的例子,河南的门户可以用这样的正则表达式解析:
<。。。。 |
我们用这种C#代码遍历MacthCollection,即可得到Named Groups(这种特性只有dotNet支持):
......... |
最后会得到像这样的XML数据:
。。。。。。。。 |
组件HTMLParser会把它命名为%原来的HTML文件名%.result.xml,还存储在同一个目录下。
3.2.解析程序
解析程序的细节被包裹在
Crawler.Parser
这个C#组件接口中,让它来分析HTML网页。
使用它的好处是:
l 逻辑独立,便于调试;
l C#的正则表达式支持Group特性,非常强大,这样我们可以兼容各种电信网通移动联通的不同样式页面,而且写这种分析网页代码量也少。
3.3.生成数据XML文件
解析之后,产品的各项参数按照配置文件中指定的格式输出。
在XML文件中要指定以下元素定义:
u .......
便于后续程序明白这些数据来源于哪里,要送到哪里。
3.4.通知数据自动存储层处理落地XML
XML文件落地后,需要用MSMQ消息队列来通知数据自动存储服务有新XML文件要处理了。
4 数据自动存储层-Spider.Saver
摘要:本章节简单介绍了Spider.Saver层如何解析落地XML文件,并生成SQL语句,同时插入数据库记录。
4.1. XSLT背景知识
假如说我们的业务数据XML类似于:
- .... |
那么我用如下的XSLT文件即可转换它:
。。。。 |
最后XSLT生成的SQL Script为:
。。。。 |
这样就自动生成了插入数据库的SQL脚本,这个XSLT是支持同一个Data根节点下包含多个Page的,它会相应地生成多个Insert语句。
4.2.XSLT转换线程
事先我们会起若干个XSLT转换线程,在I/O Complete Port上等候新XML文件的落地事件到来。
每个线程按照XML+XSLT的方式得到SQL脚本,然后用自身保持的数据库连接执行插入操作。
编写者:郑昀
Disclaimers:
Programmer’s Blog List: |
|
博客堂 |
|
博客园 |
|
Don Box's Blog |
Eric.Weblog() |
|
Blogs@asp.net |
|
本文档仅供参考。本文档所包含的信息代表了在发布之日,zhengyun对所讨论问题的当前看法,zhengyun不保证所给信息在发布之日以后的准确性。
用户应清楚本文档的准确性及其使用可能带来的全部风险。可以复制和传播本文档,但须遵守以下条款:
- 复制时不得修改原文,复制内容须包含所有页 ;
- 所有副本均须含有 zhengyun的版权声明以及所提供的其它声明 ;
- 不得以赢利为目的对本文档进行传播 。