随着大规模文本到图像(T2I)扩散模型的发展,用户可以更自由地通过文本指导图像生成过程。然而,要在不同的提示中保持同一主题的视觉一致性仍然是一个挑战。现有的方法通常需要对模型进行微调或预训练,以教授新词汇来描述特定用户提供的主题,这不仅耗时耗力,而且在生成图像与文本提示的对齐以及描绘多个主题时存在困难。本文提出了一种无需训练的方法ConsiStory,它通过共享预训练模型的内部激活来实现一致性主题生成,不涉及任何优化或预训练步骤。

重要的是,ConsiStory不涉及任何优化或预训练
ConsiStory通过三个主要步骤实现生成图像之间的一致性:首先是通过主题驱动的共享注意力机制(SDSA)来共享跨图像的主题特定信息;其次是通过注意力丢弃机制和从非一致性采样步骤获取的查询特征混合策略来丰富布局多样性;最后是通过特征注入机制进一步细化结果,确保跨图像的相应区域(如左眼)的特征相似性得到增强。
方法
ConsiStory方法的第一步是引入一个主题驱动的自注意力机制(SDSA),目的是在生成图像批次中共享与主题相关的模型激活信息。这种方法通过扩展自注意力,使得一个图像中的查询(Query)能够关注到批次中其他图像的主题相关的键(Key)和值(Value)。

架构概览(左图):
- 研究者们在给定一组提示(prompts)的情况下,每一步生成过程中都会在每个生成的图像
 中定位主题。
中定位主题。 - 利用到目前为止的每一步生成步骤中的交叉注意力图(cross-attention maps),来创建主题掩码(
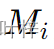 )。
)。 - 然后,他们将 U-net 解码器中的标准自注意力层替换为主题驱动的自注意力层,这些层能够在批次中的主题实例之间共享信息。
- 此外,为了额外的细化,他们还添加了特征注入(Feature Injection)。
主题驱动的自注意力(右图):
- 自注意力层被扩展,使得生成图像 中的查询(Query)也能够访问批次中所有其他图像(
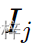 ,其中
,其中 )的键(Keys),这受到它们各自的主题掩码
)的键(Keys),这受到它们各自的主题掩码 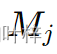 的限制。
的限制。 - 为了丰富多样性,研究者们采取了以下两个策略:
- 通过丢弃(dropout)削弱 SDSA,这有助于减少不同图像间共享注意力的影响,从而增强布局的多样性。
- 将查询特征(Query features)与非一致性采样步骤中得到的香草查询特征(vanilla Query features)混合,从而产生新的查询特征
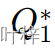 。
。
这种设计允许模型在生成图像时,不仅关注当前图像内的相关信息,还能够考虑到批次中其他图像的主题信息,从而促进主题在多图像中的一致性。同时,通过引入多样性增强策略,模型能够生成在保持主题一致性的同时,布局和风格上更为多样化的图像。
虽然SDSA能够恢复对提示的对齐并避免背景崩溃,但它可能导致图像布局之间过于相似。为了提高结果的多样性,提出了两种策略:一是结合非一致性采样步骤中获得的特征;二是通过注意力丢弃机制进一步削弱SDSA。使用香草查询特征(Vanilla Query Features)可以在不牺牲一致性的情况下增强姿势的变化。而自注意力丢弃(Self-Attention Dropout)则通过在每次去噪步骤中随机将一部分补丁设置为0,来削弱不同图像之间的注意力共享,从而促进更丰富的布局变化。
共享注意力机制显著提高了主题一致性,但可能在细微的视觉特征上存在挑战,这可能影响主题的身份。因此研究者提出了一种新颖的跨图像特征注入机制,目的是提高批次中不同图像对应区域(例如左眼)的特征相似性。首先,使用DIFT特征为图像对建立一个密集的对应图,然后根据这个图在图像之间注入特征。这个过程通过选择DIFT特征空间中余弦相似度最高的对应补丁来实现,然后将目标图像的自注意力输出层特征与其对应源补丁的特征混合。
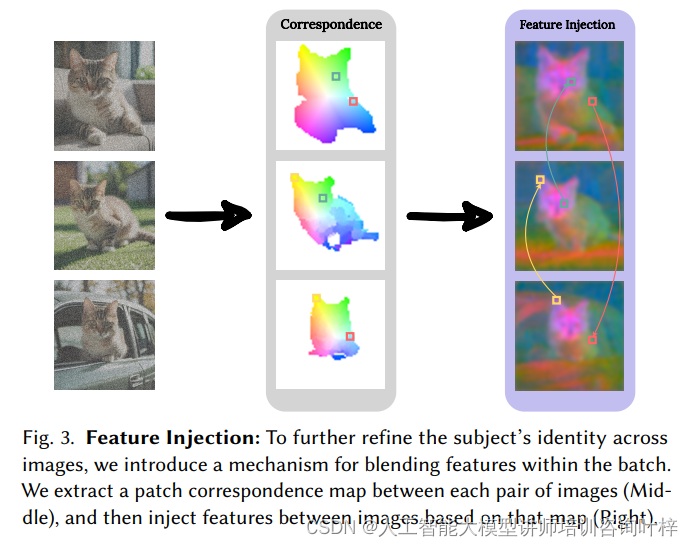
额外的优化,可以通过指定生成图像的子集作为“锚定图像”来减少方法的计算复杂性。在SDSA步骤中,不是在所有生成图像之间共享键和值,而是只允许图像观察来自锚定图像的键和值。类似地,在特征注入中,只考虑锚定图像作为有效的特征源。这样不仅可以加快推理速度并减少VRAM需求,还可以通过限制扩展注意力的大小来提高大批量生成的质量。最重要的是,现在可以在新场景中重用相同的主题,通过创建一个新的批次,使用相同的提示和种子重新创建锚定图像,但非锚定提示已经改变。
基于个性化的方法在保持单个图像中多个主题的一致性方面,ConsiStory可以通过简单地合并主题掩码来实现多主题一致性生成。当主题在语义上不同时,它们之间的信息泄露不是问题。这是由于注意力softmax的指数形式,它作为一个门控,抑制了不相关主题之间的信息泄露。同样,在特征注入期间阈值化对应图也会产生防止信息泄露的门控效果。
实验
研究者确立了几个基线模型以进行比较。这些包括:(1) 未经调整的SDXL模型作为起点;(2) 基于优化的个性化方法,这些方法通过微调模型的部分结构来使模型学习描述新主题的词汇,例如文本反转(TI)和DreamBooth-LoRA(DB-LORA);(3) 基于编码器的方法,它们通过接受单个图像作为输入,然后为扩散模型提供条件码,如IP-Adapter、ELITE和E4T。除了ELITE之外,所有这些基线都是基于预训练的SDXL模型。对于ConsiStory,研究者采用了两个锚定图像并设置了0.5的丢弃率。
研究者通过定性比较展示了ConsiStory在保持主题一致性和遵循文本提示方面的卓越性能。如图4所示,ConsiStory能够在不同的初始噪声输入下生成多样化且一致的图像集合。相比之下,基于优化的个性化方法在训练图像上的拟合效果要么过强导致缺乏变化,要么不足导致无法维持一致性。IP-Adapter在匹配复杂提示时也显示出了困难,特别是当涉及到风格变化时。ConsiStory成功实现了主题的一致性和文本对齐。



研究者进一步使用自动化指标进行了定量评估。他们使用每个基线生成了100组图像,每组包含5张在不同提示下描绘同一主题的图像。评估用的提示是利用ChatGPT生成的,包括主题描述、场景描述和风格描述三个部分。研究者使用CLIP分数来衡量生成图像与条件提示之间的相似度,并使用DreamSim来评估图像间的相似性,特别关注了主题一致性。

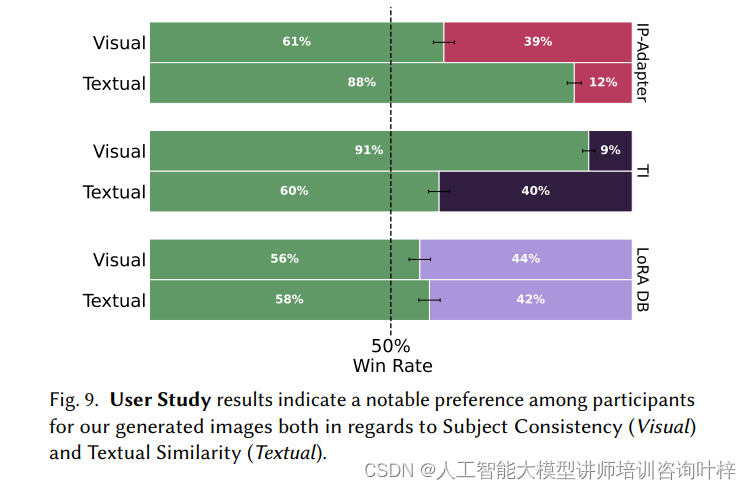
尽管ConsiStory是一种无需训练的方法,但通过大规模用户研究,研究者发现用户通常更偏好ConsiStory生成的图像,无论是在主题一致性还是文本对齐方面。用户研究采用了两种问题类型:(1) 主题一致性,用户需要选择展示同一主题特征的图像集合;(2) 文本对齐,用户需要选择最符合文本描述的图像。

研究者还对主要方法的运行时间进行了分析,重点是它们达到一致性主题的时间(TTCS)。ConsiStory实现了最快的TTCS结果,即在H100 GPU上生成两个锚定图像和基于新提示的图像仅需32秒,这一速度是现有最先进方法的25倍。
为了评估ConsiStory中不同组件的影响,研究者进行了消融研究,涉及SDSA步骤、特征注入(FI)、注意力丢弃和查询特征混合等组件。定性和定量结果表明,去除这些组件中的任何一个都会导致一致性降低。
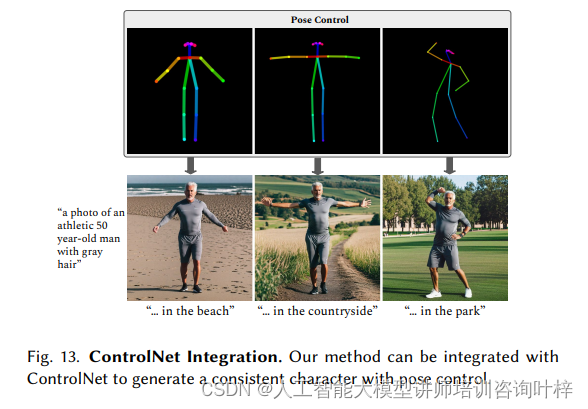
研究者还展示了ConsiStory与现有引导生成工具如ControlNet的兼容性,并演示了无需训练的个性化,即ConsiStory能够在没有任何调整或编码器使用的情况下实现个性化。

图 11 展示了 ConsiStory 方法与 ControlNet 的集成能力。ControlNet 是一种用于引导图像生成的工具,它允许用户通过控制特定参数来影响生成图像的特定方面,例如姿势或布局。

图 12 展示了 ConsiStory 方法的一个扩展应用——无需训练的个性化(Training-Free Personalization)。这项技术允许用户使用少量特定主题的图像来生成一致性高的新图像,而无需对模型进行额外的训练或调整。
ConsiStory通过其创新的架构和策略,在保持主题一致性和文本对齐方面展现出了卓越的性能,同时大幅提高了图像生成的速度,减少了对计算资源的需求。然而,这项技术也存在一些局限性。其一ConsiStory依赖于通过交叉注意力图准确定位图像中的主题,这在处理某些不寻常的风格或复杂场景时可能会遇到挑战。其次,该方法在分离主题的外观和风格方面仍有困难,这限制了它在多样化风格生成上的能力。尽管在减少模型偏见方面取得了进展,但SDXL模型本身的某些倾向可能仍然存在,这需要进一步的研究和改进。

论文链接:https://arxiv.org/abs/2402.03286